近日,Williamhill威廉希尔浪潮williamhill中国通用智能团队的研究论文“Peak-Return Greedy Slicing: Subtrajectory Selection for Transformer-Based Offline RL”被国际机器学习顶级会议International Conference on Learning Representations(ICLR)正式录用。Williamhill威廉希尔为论文第一单位,Williamhill威廉希尔徐志伟为论文第一作者。该成果是Williamhill威廉希尔在离线强化学习与序列决策建模方向的又一项重要研究进展。
学界普遍认为,离线强化学习是推动智能体在真实复杂场景中安全落地的关键技术路径之一。该方法通过仅依赖历史数据进行学习,避免了高成本或高风险的在线交互。然而,现有基于Transformer的离线强化学习方法通常以完整轨迹及最终回报作为训练信号,难以有效识别和重组轨迹中隐含的高价值决策片段,制约了模型在复杂、长时序任务中的性能上限。
针对上述瓶颈问题,论文提出了峰值回报贪心切片框架(PRGS),在时间步层面对离线轨迹进行精细化建模,显式挖掘并利用高质量子轨迹信息,突破了传统以整条轨迹为单位的学习范式。该框架由三部分构成:一是基于最大均值差异(MMD)的分布式回报估计器,对单步状态-动作对的潜在回报进行乐观估计;二是基于回报峰值的贪心式子轨迹切片策略,在时间步层面递归提取高价值决策片段用于训练;三是在推理阶段引入自适应历史截断机制,使测试过程与子轨迹训练范式保持一致,有效缓解训练与推理不匹配问题。
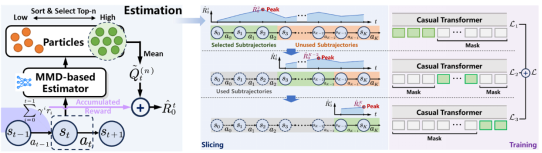
在实验评估方面,论文在D4RL连续控制任务、BabyAI自然语言指令跟随环境以及AuctionNet广告竞价场景上进行了广泛验证。结果表明,PRGS能够在多种Transformer-based离线强化学习方法上实现稳定且显著的性能提升,平均增幅超过15%。相关成果不仅丰富了离线强化学习与生成式决策模型的研究体系,也为机器人控制、广告出价等实际工业应用提供了有力支撑。

ICLR是机器学习与表示学习领域公认的国际顶级会议,与NeurIPS、ICML并列为人工智能领域最具影响力的三大会议之一。ICLR重点关注深度学习、强化学习、生成模型等前沿方向,其录用论文通常代表相关研究方向的最新进展与发展趋势。




